H-index 和大牛
在学术圈里,我们经常听到一个耳熟能详的词,大牛。 所以大牛是什么? 多大的牛才是大牛呢? 我的博士师兄是大牛吗?我的导师是不是大牛? 爱因斯坦是不是大牛?
在科研领域,凡是喜欢量化,对吧。 今天,我们就来聊聊一个衡量大牛的重要指标—— h-index(h 指数),让你见识一下大牛。
什么是 h-index?
h-index 是对学者论文生产力和研究影响力的粗略概括。论文生产力通过论文数量来量化,研究影响力则通过学者的出版物被引用的次数来量化。因为 h 指数较高的研究人员一般会发表更多同行认为重要的论文,所以 h-index 有助于确立一些学者的在邻域内的核心地位。
说白了,h 指数就像是一张“学术成绩单”,能够大概地反映出研究者的学术贡献和影响力。
h-index 最初是由 J. E. Hirsch 在《美国国家科学院院刊》[1]的一篇文章中给出定义的,即引用次数 ≥h 的论文数量。因此,h-index=3 意味着作者至少发表过三篇文章,且其中每篇至少被引用三次。
h-index 也可以通过绘制文章的引用次数图来进行简单的表述。然后根据图表对角线与引用数据的截距确定 h 指数。
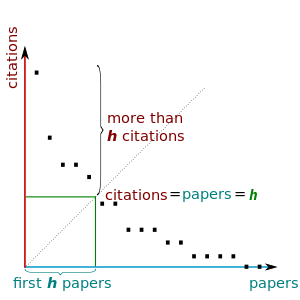
(图片来自于 Wikipedia)
我们先来看看一下大牛的 h-index:
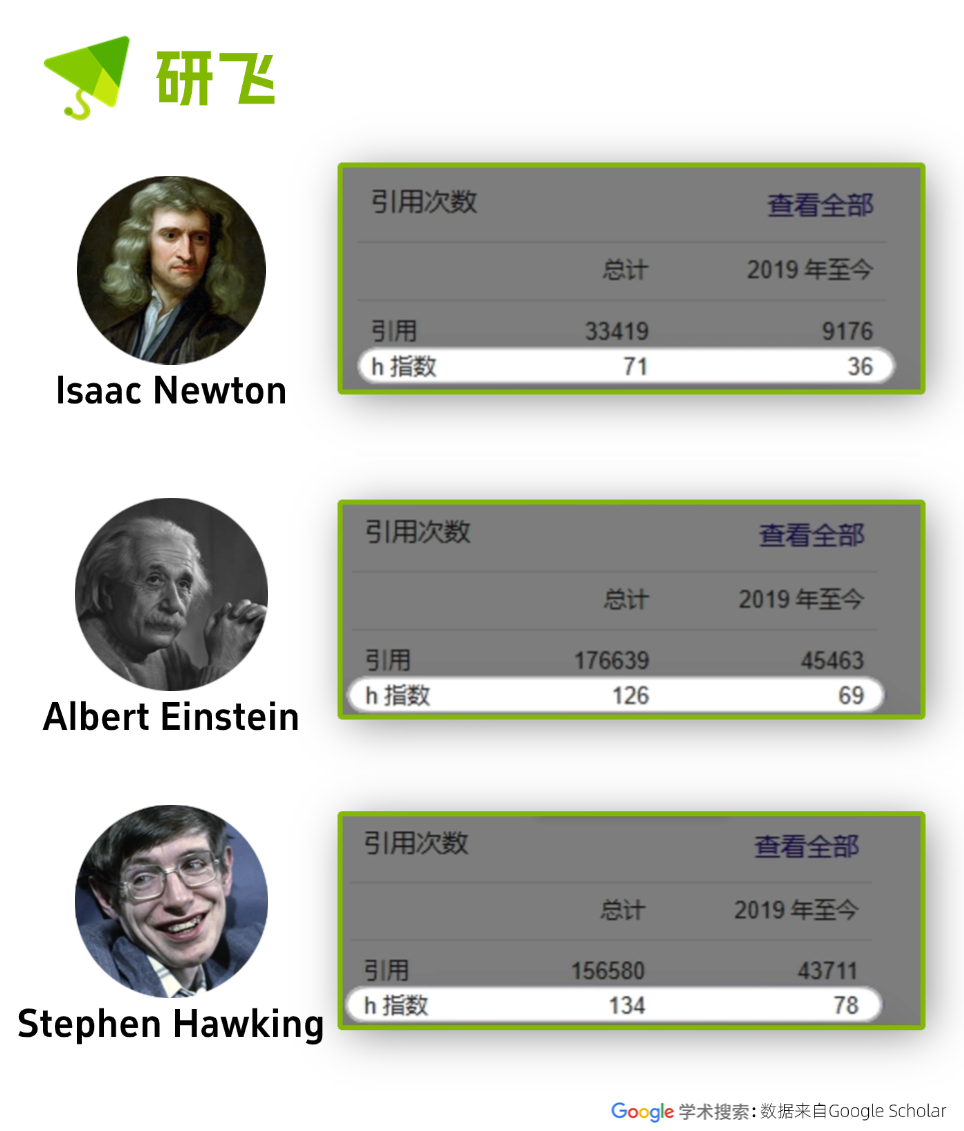
(爱因斯坦、霍金、牛顿的 h-index)
如何计算你的 h-index
第 1 步:在表格中列出你目前发表的所有文章。
第 2 步:收集每篇文章被引用的次数。
第 3 步:根据论文被引用的次数进行排序。
第 4 步:现在可以通过查找列表中排名大于引用次数的条目来得出 h 指数。
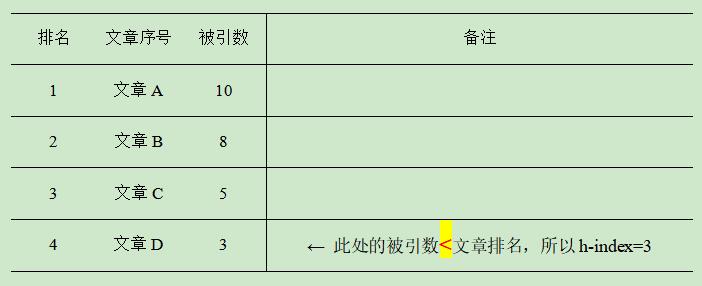
举例来说,如果一个学者有四篇论文,它们的引用次数分别为 10、8、5 和 3,那么在按照引用次数排序后,我们从前往后查找。第一篇论文引用次数为 10,大于其序号 1;第二篇论文引用次数为 8,大于其序号 2;第三篇论文引用次数为 5,大于其序号 3;但第四篇论文的引用次数为 3,小于其序号 4。
因此,该学者的 h-index=3,表示他至少有 3 篇论文分别被引用了至少 3 次。
下面是一个表格示例,其中的文章按引用次数排序,可以得到 h-index=3。
如果你论文数量足够大,不方便手动计算,那么有例如 Scopus、Web of Science 和 Google Scholar 等学术平台可以提供引用次数数据并自动计算 h-index 。
下图就是著名物理学家杨振宁在 Scopus 和 Google Scholar 上的 h-index。
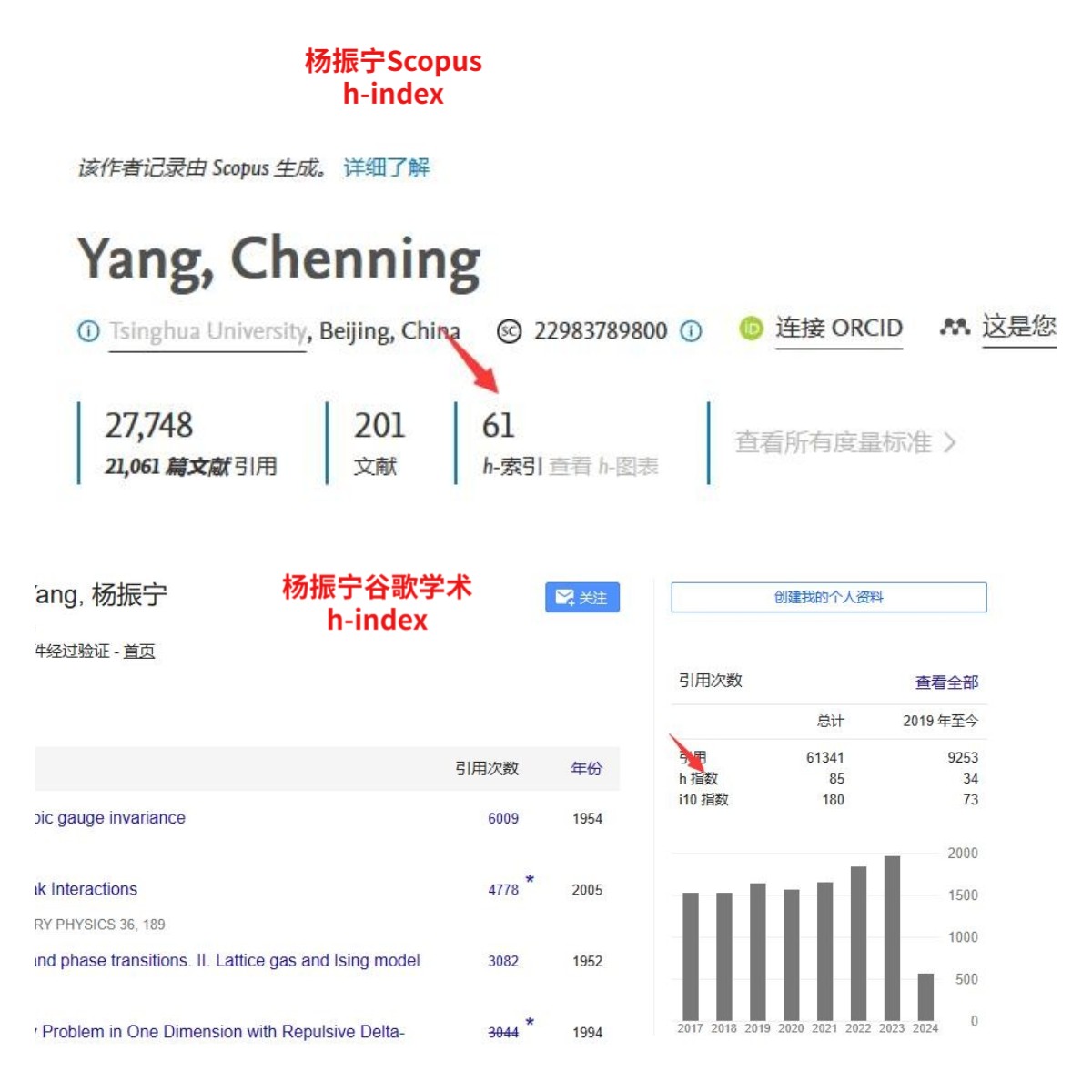
我们会发现, Google Scholar 的 h-index 通常会偏高。 因为 Google Scholar 包含的出版物数量通常更多,不知名的期刊,未被 Scopus 或者 SCI 索引的期刊,学位论文都算,那可不就要高一点。
所以,建议你去 Google Scholar 查一下你的 h-index, 天底下最大的了。
h-index 的价值
一般只有学者持续产出高质量学术成果时,h-index 才会增加。 如果研究者在 h-index=3 之后发表了另一篇被引用了 4 次的论文,那么 H 指数就会增加到 4。但是,如果添加的论文引用次数较少,h-index 则不会增加。 这就体现出了 h 指数对研究者长期学术贡献的认可,而不是仅仅看重某一篇或几篇论文的短期影响。
h-index 相对不容易受到极端值的影响。 比如,如果一篇排名最高的文章被引用了 1000 次,这并不会改变研究者的 h-index 。 这是因为 h-index 计算的是至少有 h 篇论文分别被引用了至少 h 次,极端的高引用次数并不会改变这个阈值。
h-index 永远不会大于作者发表的论文数量。 要拥有 20 的 h-index,作者必须至少发表了 20 篇文章,并且每篇文章至少被引用了 20 次。 这进一步强调了 h-index 对研究者长期、持续贡献的要求,而不是仅仅依赖少量高被引论文,或者是刷很多无意义没人看的文章。
虽然我们不需要天天盯着自己的 h-index,但是 h 指数的提升的确值得庆祝。至于它是值得开一瓶茅台,还是点一杯 9.9 块的咖啡,这取决于你自己。总之,一个很高的 h-index 是值得放在你的 CV 里的。当然,即使你不放,基金或者招聘委员通常也都会去查。
H-index 能代表学术成就吗?
答案肯定是否定的!人们意识到了 h-index 的缺陷,也有很多人尝试解决缺陷,就连 Hirsch 本人近期也指出了他认为的 h-index 的几点不足[2]:
1.它忽略了科研人员除了与 h-index 有关的其他研究
2.不同学科领域之间的 h-index 可比性较弱
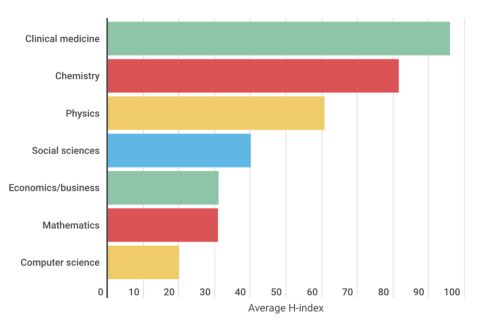
根据 2014 年的一项研究[3],对 2307 位高被引研究人员进行分析后发现,不同学科领域的 h 值存在显著差异。临床医学和化学领域的研究者通常拥有较高的 h-index ,而数学和计算机领域的研究者则相对较低。
这种差异在很大程度上是由于不同学科的研究特性、引用习惯以及学术规模等因素所致,因此直接使用 h 指数进行跨学科的比较并不准确;
3.h-index 在计算过程中忽略了作者间的贡献差异以及自引现象的影响
在学术研究中,第一作者与其他作者的贡献量往往存在显著差异,而不同合作者之间的科研水平也可能大相径庭。然而,h 指数的计算并未考虑到这些因素,从而可能导致对某些研究者的评价出现偏差。
4.h-index 不考虑引用的质量
一篇 Nature 的文章引用和一篇硕士论文的引用都算一个,甚至自己引自己也算一个,所以如果你想拼命提升自己的 h-index,那只要号召自己的同门和亲朋好友多引用自己的文章即可,这就导致 h-index 一定程度上是可以刷的,这种虚假的数据看起来可能很好笑。 毕竟即使你的 h-index 和 爱因斯坦一样,你还是少一个广义相对论这样的大作。
5.h-index 加剧了内卷
要想提升 h-index, 要做的事情就是两个: 1. 发更多的文章 2. 让更多的人引用自己的文章。 如果这个数据不是自然增长,因为对科研的热爱,通过做更好的研究,发表更好的文章,而是拼命的刷数据,那么你也是可以刷的。 就好像我前面提到的,你可以呼朋唤友,搞学术圈子,做"学术交流", 卷死其他人, 那么很显然就本末倒置了。
学术圈子里,像 h-index 一样被人追求的另外一个指标大概就是所谓影响因子了。所谓有人的地方就有江湖,有指标就有人刷。 尽管学界不断尝试提出各种替代性的评价标准,但至今仍未有哪个指标能够完全取代 h-index。想要实现科学评价体系完全摆脱人为偏见,纯粹以客观量化的方式评价研究的价值和学者的贡献,这无疑是一个近乎乌托邦的追求,好在这也正是科学家的追求,毕竟如果不量化,那么我的本科学弟也可以是学术大牛,如果他老爸是个大人物的话。
References:
[1]Hirsch JE. An index to quantify an individual’s scientific research output[J]. Proc. Natl. Acad. Sci. U.S.A., 2005, 102(46) : 16569–16572.
[2]Hirsch JE. Superconductivity, what the H? the emperor has no clothes[J]. Int. J. Mod. Phys. B, 2023, 38(07).
[3]Malesios CC, Psarakis S. Comparison of the h-index for different fields of research using bootstrap methodology[J]. Qual Quant, 2012, 48(1) : 521–545.